在系列3和系列4我讲了关于一个基本流程下,RAG的提高准确率的关键点,那么接下来,我们再次讲解2个方面,这2个方面可能与RAG的准确率有关系,但是更多的它们是有其它用途。本期先来讲解RAG路由。
目录
- 1 基本思想
- 2 Logical routing
- 2.1 基本思想
- 2.2 代码演示
- 3 Semantic routing
- 3.1 基本思想
- 3.2 代码演示
1 基本思想
说起路由我们最熟悉不过,无论是代码中通过switch语句或者网络中通过网关等方式,我们可以实现代码逻辑或者一个请求去分发到不同的模块或者服务中。那么RAG的路由又有什么不一样。
我们知道传统的路由可能是通过匹配字符串内容相同的模式去分发的,但是RAG路由是通过大模型语义去做匹配,也就是通过理解请求或者查询的字符串的语义去匹配对应的分发。
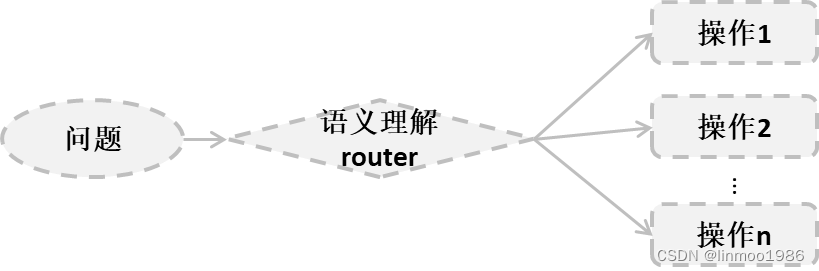
RAG routing某种程度上可以提高RAG的准确率,但是其更大的功能是提升整个RAG系统的功能性。因为通过语义理解之后,后面的操作可能是通过不同路由到不同数据源、或者调用API工具、甚至是其它Agent等等,这样你的RAG就更为丰富,因此RAG routing的作用如下:
- 增加RAG系统功能丰富度。你可以增加多种数据库查询、可以增加多种API、可以增加多个Agent等等,常见于搜索助手、客服系统、问答系统等等
- 解耦RAG与其它系统。其实路由一般都有解耦的作用,你可以一个模块一个模块的上线,比如开始你的搜索系统只是一个文本搜索,后面慢慢可以增加图片生成、语言生成、翻译等功能,而且是以模块化方式
- 提高RAG准确度。这个前面已经提到过,如果你的RAG只是一个基于某个数据库检索后生成答案,有可能你的数据库知识有限,搜索不到相关信息,这是你可能需要去网上找其他资料等等,这样可能能更好提高你的RAG准确度
一般来说,基于语义理解的RAG routing分为2种不同实现模式:
- Logical routing:使用大模型对问题进行推理,通过理解的内容并选择更合适的方式。
- Semantic routing:将问题和一组prompt向量化,让后计算其相似性选择合适的prompt。
2 Logical routing
2.1 基本思想
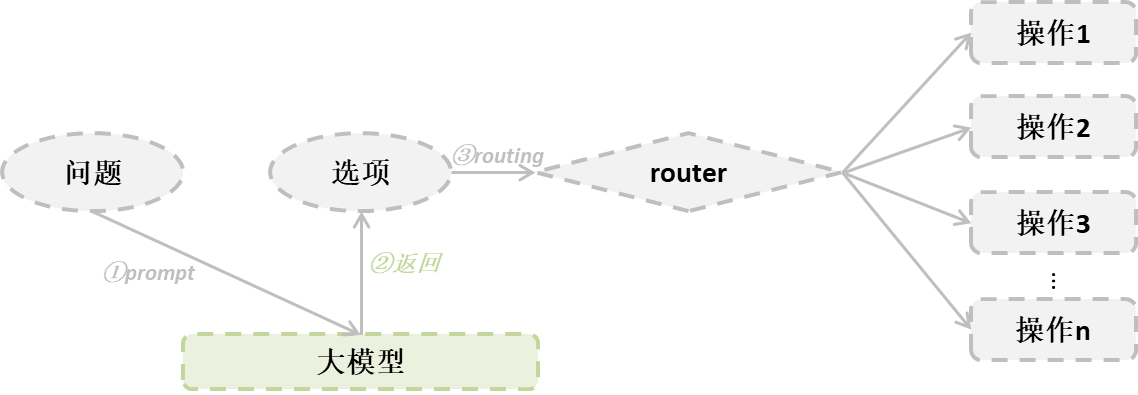
这是一种基于大模型的推理能力,将你要查询的问题进行逻辑推理,最终选择选项中最为接近的答案,当然有可能答案中并不存在,那么我们可以设置一些兜底方案,比如直接回答不知道。步骤如下:
- 让大模型对问题进行语义分析,选出对应选项
- 通过选项,进入路由引擎,对其进行路由选择最终操作
2.2 代码演示
这里只是简单演示以下流程,通过一个prompt,让大模型分析问题语义,给出路由的选项,然后再通过路由函数进行选择最终操作。其中prompt和路由函数在实际应用中就是更为复杂或者使用路由引擎来代替。
前置条件:
- 这里采用智谱AI的API接口,因此可以先去申请一个API KEY(当然你使用其它模型也可以,目前智谱AI的GLM4送token,就拿它来试验吧)
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnableLambda
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 前置工作:创建llm
llm = ChatOpenAI(
temperature=0.01,
model="glm-4",
openai_api_key="你的API KEY",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 第一步:通过大模型进行对问题的语义分析,将结果返回出来
system = """根据用户的问题,将其分类为:'python代码问题'、'java代码问题'、'js代码问题'。如果无法分类,则直接回答不知道。
问题:{question}
输出格式直接返回选项内容
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
router = prompt | llm | StrOutputParser()
question = """为什么下面这段代码报错,错误信息是System.out.printIn找不到
public class HelloWorld {
public static void main(String[] args) {
System.out.printIn("Hello World");
}
}
"""
response = router.invoke({"question": question})
print(response)
# 第二步:根据返回结果,进行router选择,这里是将前面第一步也串联起来
def route_fun(result):
if "python代码问题" in result:
return "由python文档库查询"
elif "java代码问题" in result:
return "由java文档库查询"
elif "js代码问题" in result:
return "由js文档库查询"
else:
return "无法识别"
final_chain = router | RunnableLambda(route_fun)
print(final_chain.invoke({"question": question}))
3 Semantic routing
3.1 基本思想
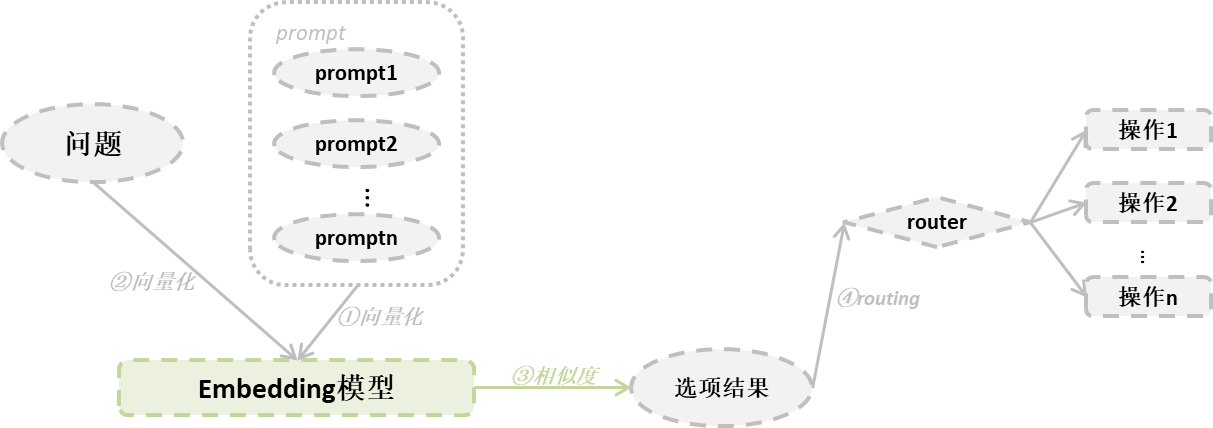
这个方法是将问题和一组prompt向量化,让后计算其相似性选择合适的prompt。其实在前面问题优化中,问题在向量数据库中查询最接近答案的方式是一样的,只不过将向量数据库和相似度用于路由选择。步骤如下:
- 将问题和一组事先准备好的prompt向量化
- 对其问题与prompt直接计算相似度,取最相似的一个
3.2 代码演示
这里使用m3e-base的embedding模型将一组prompt向量化,再将查询问题向量化,计算其相似度,获得相似度最高的结果。
前置条件:
- 下载m3e-base的embedding模型
from langchain.utils.math import cosine_similarity
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_huggingface import HuggingFaceEmbeddings
# 前置工作:初始化embeddings模型
encode_kwargs = {"normalize_embeddings": False}
model_kwargs = {"device": "cuda:0"}
embeddings = HuggingFaceEmbeddings(
model_name='/root/autodl-tmp/model/AI-ModelScope/m3e-base', # 换成自己的embedding模型路径
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
# 第一步:将一组prompt进行向量化
search_template = """你是一个智能搜索机器人。
你可以通过搜索互联网内容结果并总结出最终答案。但搜索无结果是,请回答不知道
这里有一个问题:
{question}"""
picture_template = """你是一个图片生成机器人。
你很擅长将文本内容生成图片。
这里有一个问题:
{question}"""
prompt_templates = [search_template, picture_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates)
# 第二步,计算相似度
def similarity_fun(question_temp):
# 将问题向量化
query_embedding = embeddings.embed_query(question_temp["question"])
# 计算相似度
similarity = cosine_similarity([query_embedding], prompt_embeddings)[0]
most_similar = prompt_templates[similarity.argmax()]
# 选择结果
print("使用 搜索Agent" if most_similar == search_template else "使用 文生图Agent")
return PromptTemplate.from_template(most_similar)
chain = (
{"question": RunnablePassthrough()}
| RunnableLambda(similarity_fun)
)
print(chain.invoke("请生成一种80年代中国的照片"))